SPEX: Verifiability in the Age of Black-Box AI: Why Trust Needs More Than Explainability
Apr 3, 2025

TL;DR
As AI systems grow more complex and opaque, explainability alone is no longer sufficient to ensure trust. Traditional interpretability has evolved into explainable AI (XAI), but XAI struggles with non-determinism and the black-box nature of modern models. This opens the door to adversarial manipulation and undermines accountability. SPEX addresses this by introducing a verifiable computing protocol that ensures AI systems execute as intended, even if their internal workings remain opaque. Unlike XAI, SPEX doesn’t explain why a model made a decision—it proves how it was made, adding a crucial layer of integrity and trust. Together, SPEX and XAI form a complementary approach: XAI for understanding, SPEX for verification.
The Expanding Complexity of AI Systems
The rise of machine learning, and subsequently AI, large language models (LLMs), and autonomous agents—collectively referred to as AI systems—has expanded the reach of automation into domains previously considered infeasible. However, this expansion has introduced substantial complexity, characterized by statistically grounded yet opaque behaviors and increasing non-determinism.
From Interpretability to Explainability in AI
We’ve shifted from explaining interpretable decisions, such as a path in a decision tree, to attempting to rationalize the output of models with billions of parameters. The former offers clear human interpretability; the latter often requires abstraction and approximation, making complete explanations nearly impossible. This evolution has catalyzed a growing interest in explainable AI (XAI).
Security Risks and the Challenge of Non-Determinism
Simultaneously, the black-box nature of modern AI systems has expanded the attack surface for adversarial manipulation. Bad actors might tamper with these systems to reduce operational costs or gain strategic advantages. For example, a trading algorithm might incur $100 in compute to produce a high-quality execution sequence but could be manipulated to generate lower-quality outputs at a fraction of the cost. With millions of such transactions, these shortcuts can lead to significant gains for dishonest operators. In some cases, an operator might even bias outcomes to serve their own interests over those of their clients. But how can one prove that the system behaved as intended—especially when outputs may be non-deterministic, even under correct and honest operation?
Introducing SPEX: Verifiable Execution for AI Systems
SPEX is designed to address exactly this class of problems. It provides a verifiable computing protocol that ensures integrity and accountability in black-box AI systems, protecting against tampering and offering proof of correct execution.
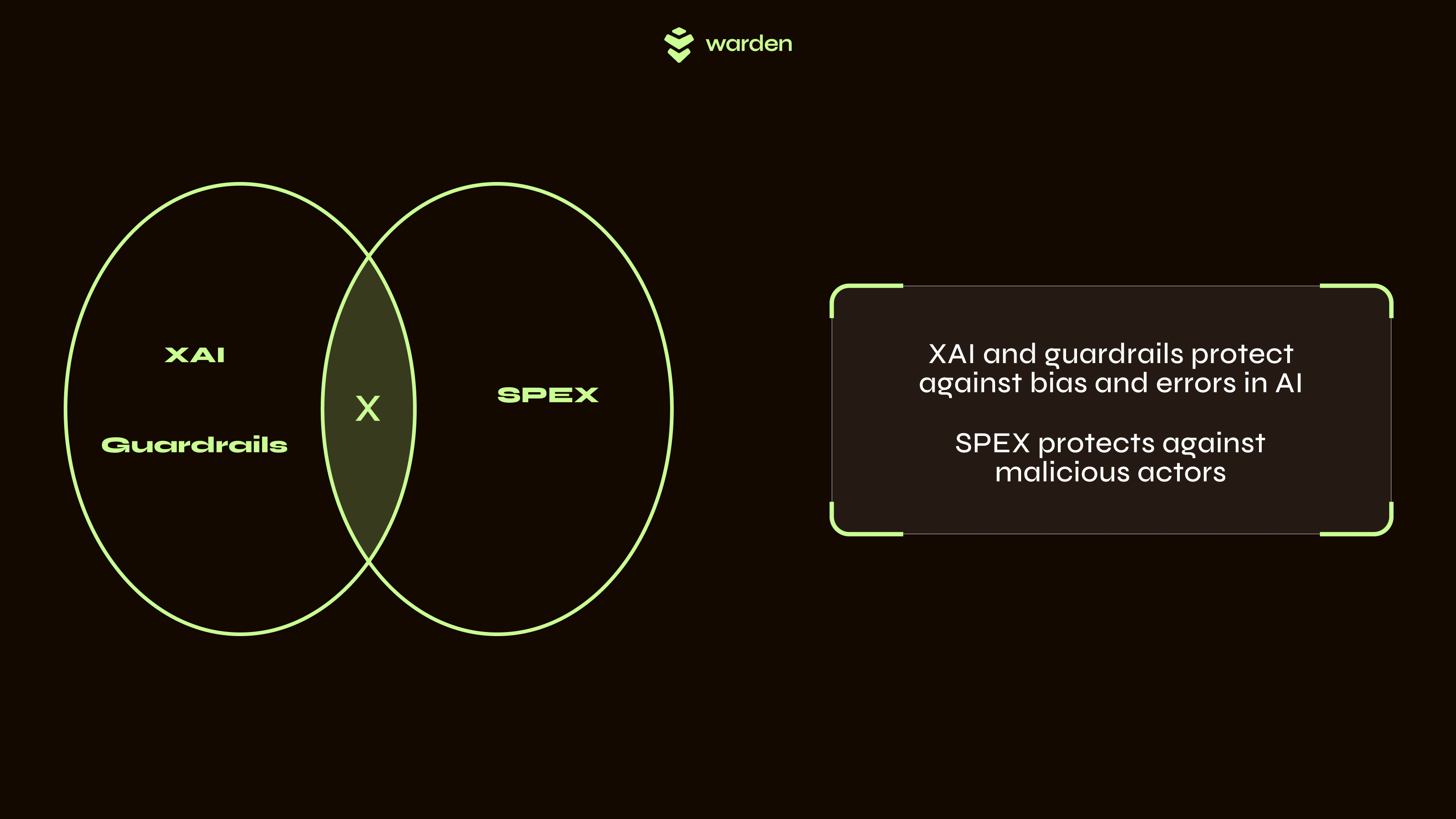
SPEX is not XAI
It is important to emphasize that SPEX is not an explainability tool. It does not aim to interpret, rationalize, or make the internal logic of AI models more transparent to human users, nor does it provide any guarantee that the outputs are fit for purpose and safe to use.
 SPEX as a complementary tool to XAI
SPEX as a complementary tool to XAI
SPEX is best understood as a complementary layer to explainable AI (XAI). While XAI aims to make model behavior more transparent and interpretable—helping users understand why a model made a certain decision—SPEX ensures that the model’s output was generated as intended, without tampering or deviation from the approved implementation. In other words, XAI builds trust through understanding, whereas SPEX builds trust through verifiability. Used together, these approaches provide a more comprehensive foundation for deploying AI in high-stakes settings: XAI enables scrutiny of the model’s reasoning, while SPEX guarantees the integrity of its execution.